 All
Articles
All
Articles Email
Analytics
Email
Analytics
Data is key to understanding what customers want and need. But sifting through mountains of data and analyzing it can prove a daunting undertaking. That’s where advanced AI tools come in. In this article, we’ll discuss natural language processing techniques (NLP) and share examples of their application, examining how they can drive your growth.
The AI revolution is coming. Today, 35% of companies report using AI in their business, an increase of four percent from 2021. And an additional 42% report that they are exploring ways to begin using AI.
No matter where you are in terms of readiness to begin adopting artificial intelligence and machine learning in your company, it’s to your organization’s benefit to learn about these emerging technologies and understand how you might be able to apply them in order to improve business outcomes.
Natural language processing, or NLP for short, is the perfect place to start.
It’s a powerful application of machine learning technology that can be used in a wide variety of industries for countless applications to help with everything from streamlining business processes to boosting efficiency to improving e-commerce customer experience and brand loyalty.
In this article, we’ll dive into everything you need to know about natural language processing including:
- What it is.
- Its advantages.
- Relevant techniques.
- Applications.
- And, finally, real-world examples.
Let’s start from the top.
What is natural language processing?
Natural language processing is a branch of artificial intelligence that aims to help computers to understand human language input in the form of text or speech.
NLP combines multiple disciplines, including computation linguistics, machine learning, deep learning, and statistics.
These technologies work together to essentially give computer software the ability to process and understand human language in the way that another human could, including its meaning, intent, and sentiment.
NLP technology is used in a variety of applications including:
- Digital assistants such as Siri.
- Speech-to-text dictation software.
- Voice-operated GPS systems.
- Customer service chatbots.
- Predictive text.
- Digital voicemail.
- Autocorrect.
- Search autocomplete.
- Email filters.
Additionally, companies are increasingly using NLP to create enterprise solutions that help businesses simplify processes, increase productivity, and streamline operations.
The benefits of employing natural language processing
It’s standard these days for companies to collect, store, process, and analyze large quantities of numerical data in order to generate valuable insights that can improve results.
Natural language processing opens up and empowers businesses to make smarter decisions that are based on larger sets of data. Further, this collection and analysis process happens quickly, especially compared to traditional methods.
For this reason, natural language processing has a number of relevant advantages.
When working with so much data, you’ll be able to generate insights to improve customer experience with the launch of new products.
On top of that, using NLP helps businesses become more efficient by automating work processes that require reviewing or analyzing texts. This frees up employees to work on other needle-moving tasks.
Taken together, you’re bound to see improved productivity, reduced costs, and an uplift in revenue.
The top techniques used in NLP
NLP is a rich field requiring the use of a number of different techniques in order to successfully process and understand human language. Below, we review and define a selection of the techniques commonly used in NLP technology.
Tokenization
Also called word segmentation, tokenization is one of the simplest and most important techniques involved in NLP.
It’s a crucial preprocessing step in which a long string of text is broken down into smaller units called tokens. Tokens include words, characters, and subwords. They are the building blocks of natural language processing, and most NLP models process raw text on the token level.
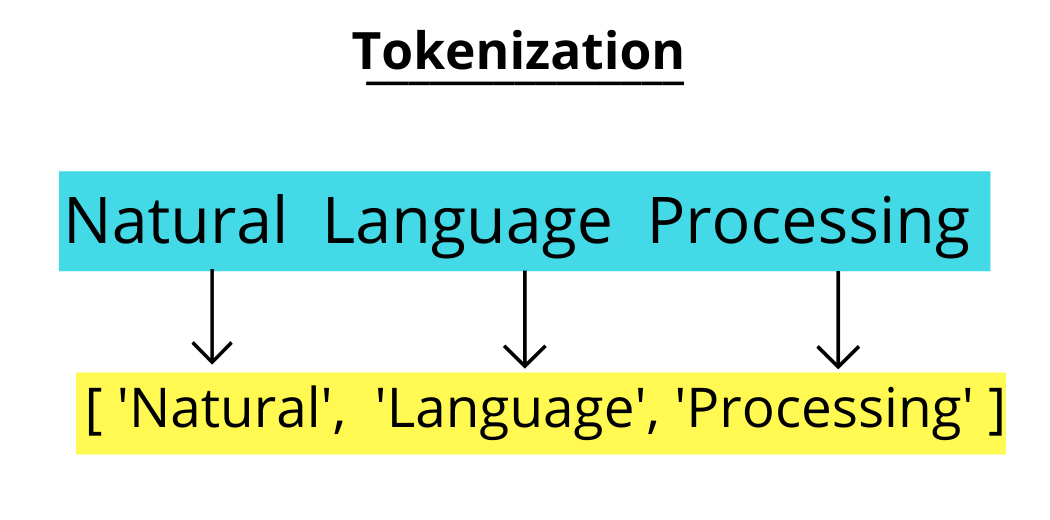
An example from Medium of how a simple phrase can be broken down into tokens.
Stemming & lemmatization
After tokenization, the next preprocessing step is either stemming or lemmatization. These techniques generate the root word from the different existing variations of a word.
For example, the root word “stick” can be written in many different variations, like:
- Stick
- Stuck
- Sticker
- Sticking
- Sticks
- Unstick
Stemming and lemmatization are two different ways to try to identify a root word. Stemming works by removing the end of a word. This NLP technique may or may not work depending on the word. For example, it would work on “sticks,” but not “unstick” or “stuck.”
Lemmatization is a more sophisticated technique that uses morphological analysis to find the base form of a word, also called a lemma.

The difference between how stemming and lemmatization work is illustrated in this image from itnext, using different forms of the word “change.”
Morphological segmentation
Morphological segmentation is the process of splitting words into the morphemes that make them up. A morpheme is the smallest unit of language that carries meaning. Some words such as “table” and “lamp” only contain one morpheme.
But other words can contain multiple morphemes. For example, the word “sunrise” contains two morphemes: sun and rise. Like stemming and lemmatization, morphological segmentation can help preprocess input text.
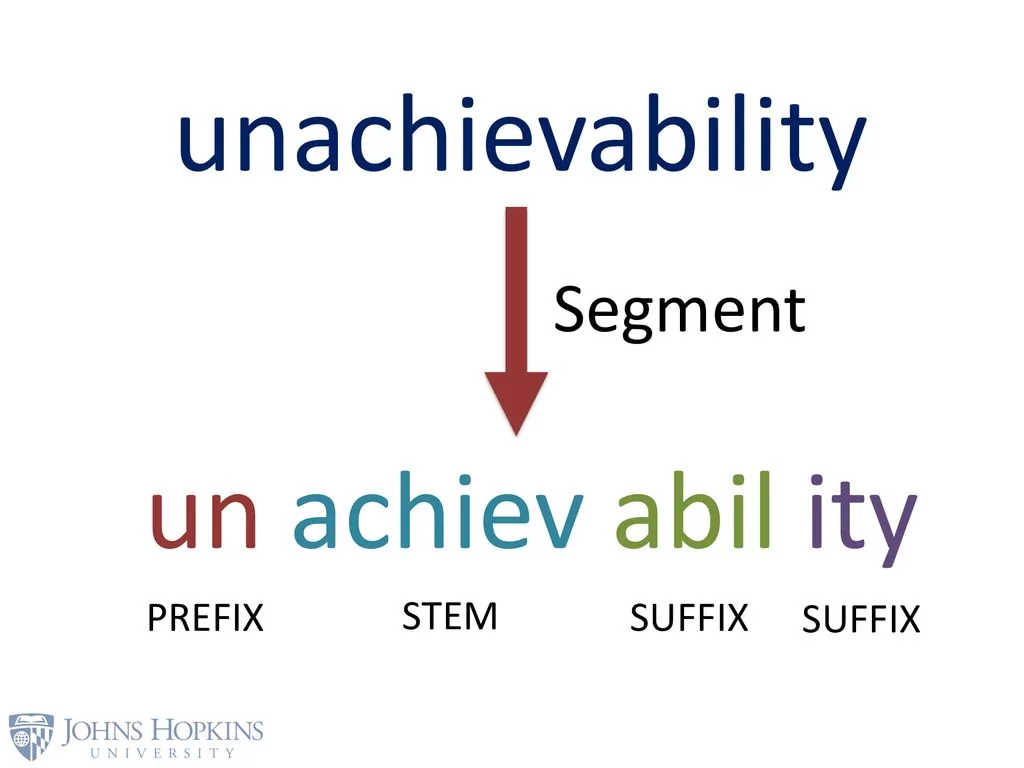
John Hopkins shows morphological segmentation by breaking the word “unachievability” into its morphemes.
Stop words removal
Stop words removal is another preprocessing step of NLP that removes filler words to allow the AI to focus on words that hold meaning. This includes conjunctions such as “and” and “because,” as well as prepositions such as “under” and “in.”
By removing these unhelpful words, NLP systems are left with less data to process, allowing them to work more efficiently. It isn’t a necessary step of every NLP use case, but it can help with things such as text classification.
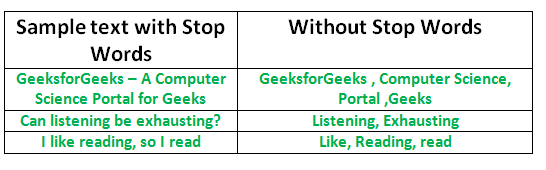
Examples from geeksforgeeks of what short phrases look like with the stop words removed.
Text classification
Text classification is an umbrella term for any technique used to organize large quantities of raw text data. Sentiment analysis, topic modeling, and keyword extraction are all different types of text classification. And we’ll talk about them shortly.
Text classification essentially takes unstructured text data and structures it, preparing it for further analysis. It can be used on nearly every text type and help with a number of different organization and categorization applications.
In this way, text classification is an essential part of natural language processing, used to help with everything from detecting spam to monitoring brand sentiment.
Some possible applications of text classification include:
- Grouping product reviews into categories based on sentiment.
- Flagging customer emails as more or less urgent.
- Organizing content by topic.
Sentiment analysis
Sentiment analysis, also known as emotion AI or opinion mining, is the process of analyzing text to determine whether it is generally positive, negative, or neutral.
As one of the most important NLP techniques for text classification, sentiment analysis is commonly used for applications such as analyzing user-generated content. It can be used on a variety of text types, including reviews, comments, tweets, and articles.
The Revuze platform employs sentiment analysis to understand how customers feel about various aspects of products. This allows companies to gain insights about consumers’ needs in real-time, and act accordingly to improve overall CX.
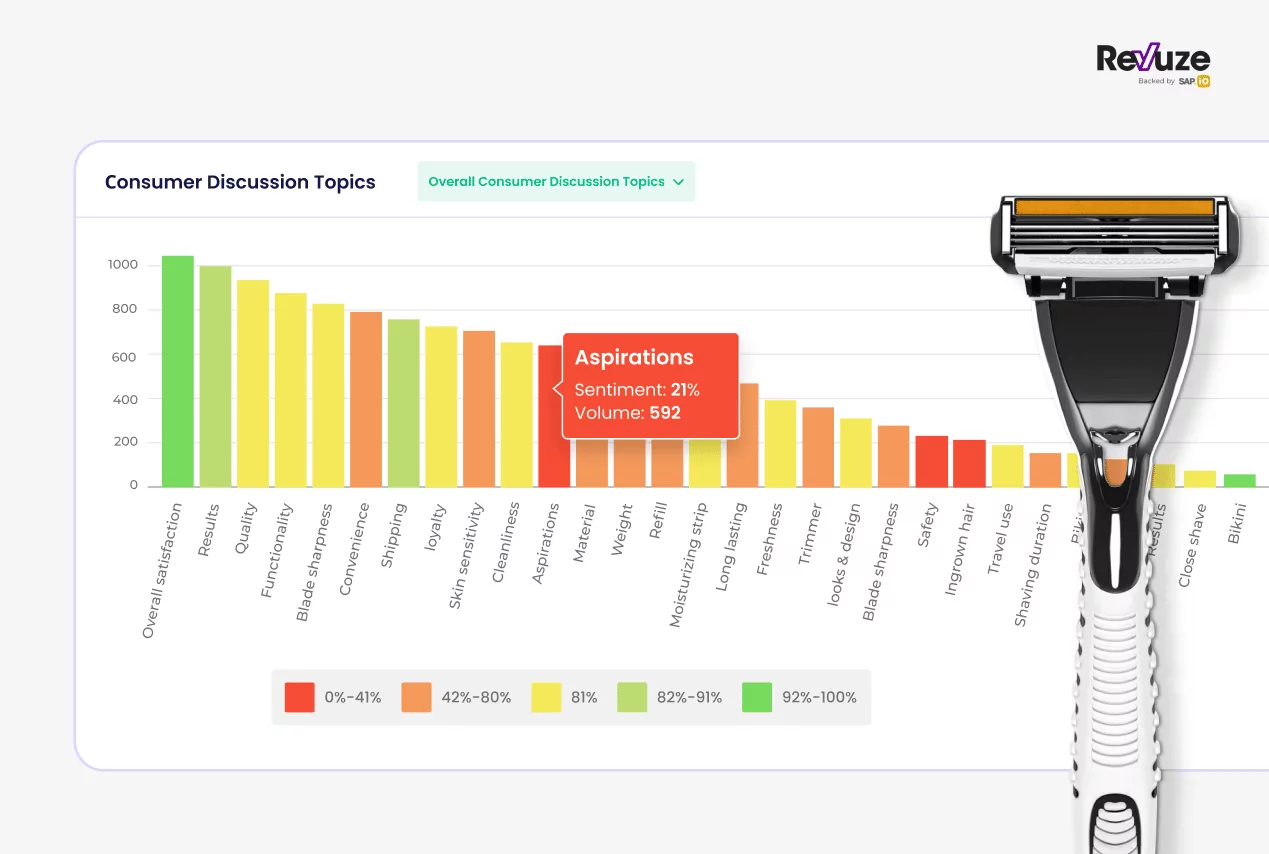
In this example from the Revuze platform, you can see how customers rate different aspects of the product.
Topic modeling
Topic modeling is a technique that scans documents to find themes and patterns within them, clustering related expressions and word groupings as a way to tag the set.
It’s an unsupervised machine learning process, meaning that it doesn’t require the documents it is processing to have previously been categorized by humans.
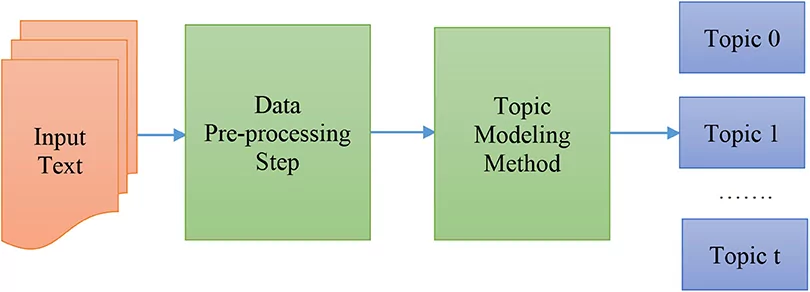
A sample NLP workflow from Frontiersin demonstrates how Input text is proprocessed before undergoing topic modeling, which breaks it into several topics.
Keyword extraction
Keyword extraction is a technique that skims a document, ignoring the filler words and honing in on the important keywords. It is used to automatically extract the most frequently used and essential words and phrases from a document, helping to summarize it and identify what it’s about.
This is highly useful for any situation in which you want to identify a topic of interest in a textual dataset, such as whether there is a problem that comes up again and again in customer emails.
Text summarization
This NLP technique summarizes a text in a coherent way, and it’s great for extracting useful information from a source. While a human would have to read an entire document in order to write an accurate summary of it, which takes quite a bit of time, automatic text summarization can do it much more quickly.
There are two types of text summarization:
- Extraction-based – This technique pulls key phrases and words from the document to make a summary without changing the original text.
- Abstraction-based – This technique creates new phrases and sentences based on the original document, essentially paraphrasing it.
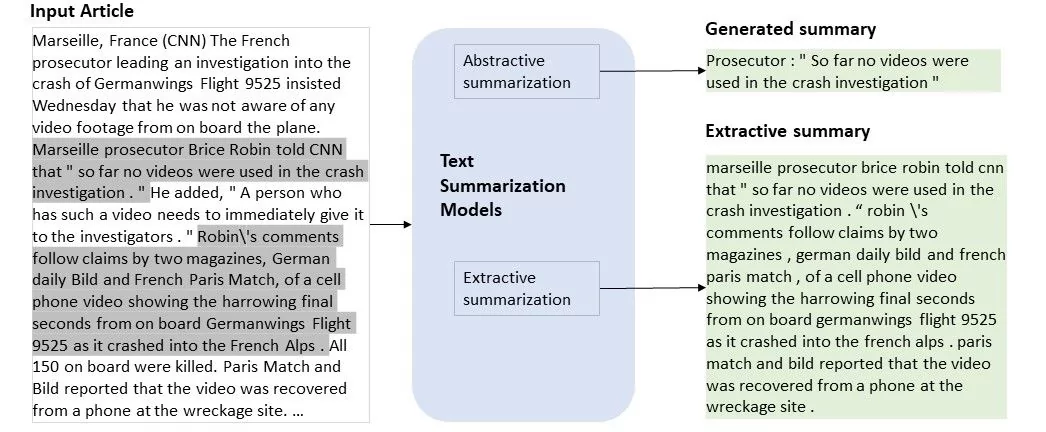
An example from the Microsoft tech community of how the two types of text summarization work.
Parsing
Parsing is the process of figuring out the grammatical structure of a sentence, determining which words belong together as phrases and which are the subject or object of a verb. This NLP technique offers additional context about a text in order to help with processing and analyzing it accurately.
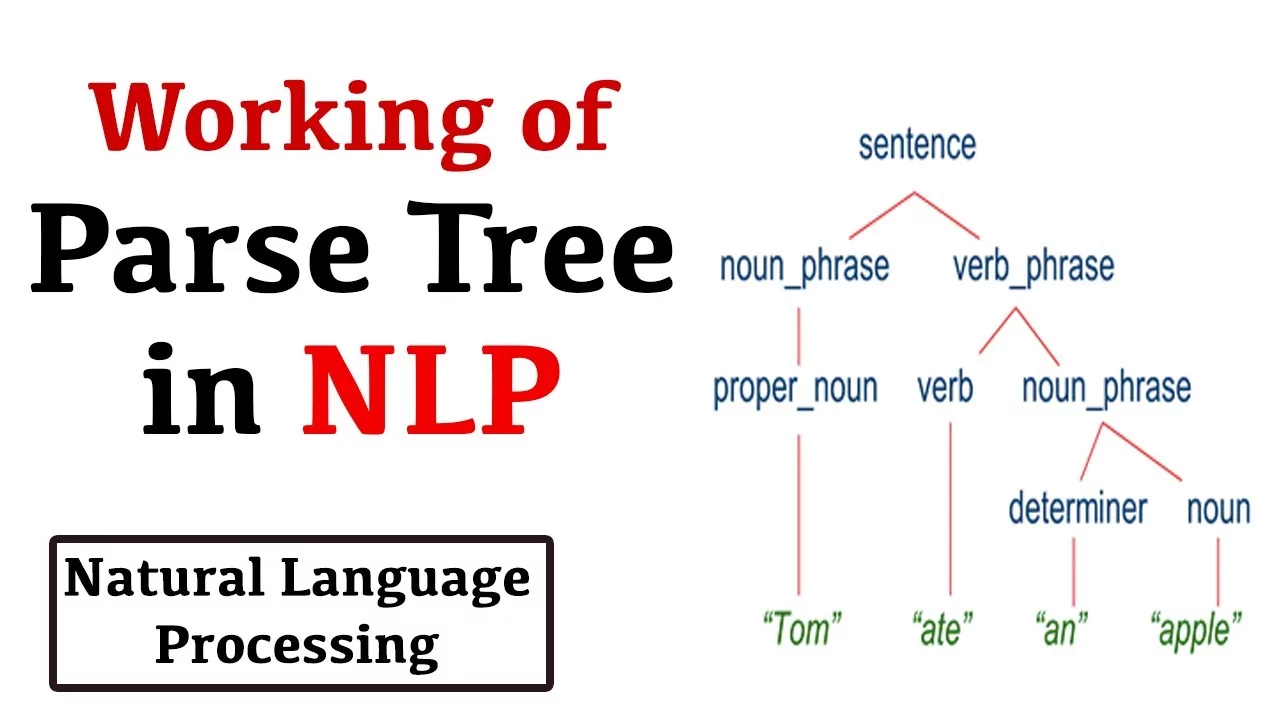
This is how parsing might work on a short sentence.
Named entity recognition
Named entity recognition (NER) is a type of information extraction that locates and tags “named entities” with predefined keywords such as names, locations, dates, events, and more.
In addition to tagging a document with keywords, NER also keeps track of how many times a named entity is mentioned in a given dataset. NER is similar to keyword extraction, but the extracted keywords are put into predefined categories.
NER can be used to identify how often a certain term or topic is mentioned in a given data set. For example, it might be used to identify that a certain issue, tagged as a word like “slow” or “expensive,” comes up again and again in customer reviews.

A sample by Shaip of how named entity recognition works.
TF-IDF
TD-IDF, which stands for term frequency-inverse document frequency, is a statistical technique that determines the relevance of a word to one document in a collection of documents. It works by looking at two metrics: the number of times a word appears in a given document and the number of times the same word appears in a set of documents.
If a word is common in every document, it won’t receive a high score, even if it appears many times. But if a word frequently repeats in one document while rarely appearing in the rest of the documents in a set, it will rank high, suggesting it is highly relevant to that one document in particular.
Natural language processing applications
NLP is a quickly developing technology with many different applications for organizations of every kind. Some of the different ways a business can benefit from NLP include:
- Machine translation – Using NLP, computers can translate large amounts of text from a target to a source language, which can be used for customer support, data mining, and even publishing multilingual content.
- Information retrieval – NLP can be used to quickly access and retrieve information based on a user’s query from text repositories such as file servers, databases, and the internet.
- Sentiment analysis – This NLP technique can be used to monitor brand and product sentiment to help with customer service and product sentiment, among other applications.
- Information extracting – This process, which includes retrieving information from unstructured data and extracting it into structured, editable formats, can be used for business intelligence, including competitive intelligence.
- Question answering – Question answering uses NLP to give an answer to a question asked in natural human language and can be used for chatbots and customer support.
Natural language processing examples
Here are just a few more concrete examples of ways an organization might apply NLP to its business processes.
NLP in ChatGPT
One of the most popular recent applications of NLP technology is ChatGPT, the trending AI chatbot that’s probably all over your social media feeds. ChatGPT is fueled by NLP technology, using a multi-layer transformer network to generate human-like written responses to inquiries submitted in natural human language. ChatGPT uses unsupervised learning, which means it can generate responses without being told what the correct answer is.
ChatGPT is an exciting step forward in the application of NLP technology for businesses and individuals alike, with many saying it can rival even Google. Possible uses for ChatGPT include customer service, translation, summarization, and even content writing.
NLP for customer experience analytics
Using NLP for social listening and customer review analysis can lead to tremendous insight into what customers are thinking and saying about a brand and its products. With sentiment analysis and text classification, companies can:
- Understand general sentiment about the brand – Does the public feel positively or negatively about us?
- Identify what customers like and dislike about a service or product.
- Learn what new products customers might be interested in.
- Know which products to scale and which to pull back on.
- Discover insights that can be used to improve customer experience and boost customer satisfaction.
For example, let’s say spicy chocolate brand Shock-O just released a new Popping Jalapeno Chocolate and wants to get a sense of whether or not customers like it. Shock-O can use an NLP-powered tool to analyze customer sentiment and learn what people are saying about the Popping Jalapeno Chocolate, whether they speak about it positively or negatively, and what themes come up again and again in reviews of this product.
All of this information can then be used to determine whether to continue producing Popping Jalapeno Chocolate, whether to increase or decrease its production of it, whether to make it spicier or less spicy, etc.
NLP for customer service
90% of customers believe that it is essential or very important to receive an immediate response when they have a question. Yet human customer service representatives are limited in availability and bandwidth.
This is just one reason why NLP-powered chatbots are growing in popularity. By being able to properly understand and analyze customer inquiries, chatbots can offer the necessary answers to questions, helping to improve customer satisfaction while cutting down on agents’ workload.
NLP can also be used to process and analyze customer service surveys and tickets in order to better understand what issues customers are having, what they’re happy with, what they’re unhappy with and more. All of this serves as crucial data for boosting customer happiness, which will, in turn, increase customer retention and improve word-of-mouth.
NLP for recruitment
HR professionals spend countless hours reviewing resumes in order to identify suitable candidates. NLP can make this process much more efficient by taking over the screening process and analyzing resumes for certain keywords.
For example, you might set up an NLP system to flag any resume that uses the word “Python” or “leadership” for a human to review later on.
This can increase the likelihood of finding strong candidates, helping an organization fill open positions more quickly and with better talent. What’s more, it can also free up HR professionals’ time to focus on tasks that require more strategic thinking.
Conclusion
The idea that data has important insights to offer companies has been widely accepted, leading businesses to invest in various business intelligence technologies in order to improve their processes and offerings.
But if your organization is only mining numerical data, you’re missing out on a wealth of valuable information to be found in unstructured human language-based data.
Natural language processing is a powerful technology allowing text and words to be analyzed as efficiently as numbers can. By learning about and investing in NLP, you’ll be able to achieve a number of desirable outcomes, including streamlining processes, improving brand reputation and loyalty, and ultimately boosting revenue.
The next step would be taking these actionable insights and using them to further drive CX with e-commerce personalization.
